Managing the Code-WebDriver Relationship
Programmatically Driving the Browser
In order to automate tests via a browser, you'll need a tool like Selenium WebDriver, along with the appropriate programming language bindings. Note that Selenium is NOT a test framework: it is a tool to manage browser interactions, with no internal test-running capability.
If you can interact with an HTML document displayed in a browser, you will probably be able to interact to the same functional effect using a WebDriver. This can be challenging, because you have to translate user interaction to the programmatic steps and commands supported by the WebDriver and mediated by your language's bindings. The commands are explicit knowledge that you have to learn, and the sequence patterns are implicit knowledge that you have to practice in order to master.
The easiest way to start with WebDriver, in Python of course, is to run your commands in the IPython interactive shell. Assuming you have your local environment set up and configured correctly, and have the chromedriver file in the correct place locally, you can simply fire up IPython and type your valid WebDriver bindings command to control your driver. For example, we can start the driver and navigate to duckduckgo.com, then perform a search.
In [1]: from selenium import WebDriver
In [2]: browser = WebDriver.Chrome()
In [3]: browser.get('https:/duckduckgo.com')
In [4]: browser.title
Out[4]: 'DuckDuckGo — Privacy, simplified.'
In [5]: search_field = browser.find_element_by_class_name('js-search-input')
In [6]: search_field.send_keys('unconscious bias')
In [7]: search_field.submit()
In [8]: browser.title
Out[8]: 'unconscious bias at DuckDuckGo'This code in the interactive shell is live-driving the browser.[1] These commands are interacting with the WebDriver's browser instance to access the rendered page's properties and DOM and to emulate user interactions with that page. The basic pattern for this kind of user-emulated interaction is illustrated with this sequence diagram[2]:
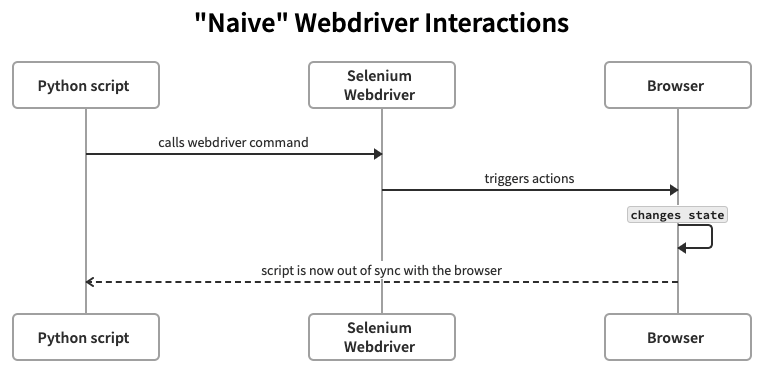
The very significant problem with this approach to driving browser interactions is the lack of mechanism to sync the script commands with the current state of the browser: when you issue a command that changes the browser state, you must then manage what the script knows about the changed browser state. The obvious example is that if you try to take action on a web-element that is no longer part of the current page's DOM, you will get an error.
A long story short: the WebDriver is mapped to the current instance of the browser, and to the contents/DOM of what that browser is currently displaying.[3] So given this information, this script is missing two things:
- checks and validations that support the script by proving that commands and actions have had the expected results
- some way of keeping the script synced with the actual state of the browser and the displayed page
You can add checks to make sure you are on the right page after an action:
In [1]: from selenium import WebDriver
In [2]: browser = WebDriver.Chrome()
In [3]: browser.get('https://www.duckduckgo.com/')
In [4]: if not browser.title == 'DuckDuckGo — Privacy, simplified.'':
...: msg = f"Expected title 'DuckDuckGo — Privacy, simplified.',"
f" but got '{browser.title}'"
...: raise RuntimeError(msg)
...:
In [5]: search_field = browser.find_element_by_class_name('js-search-input')
In [6]: search_field.send_keys('unconscious bias')
In [7]: search_field.submit()
In [8]: if not browser.title == 'unconscious bias at DuckDuckGo':
...: msg = f"Expected title 'unconscious bias at DuckDuckGo',"
...: f" but got '{browser.title}'"
...: raise RuntimeError(msg)
...:
What's changed here is that commands 4 and 8 now do a check for the page's title, and if the title doesn't match our explicit expectation, we raise an exception to kill the script. Although we aren't handling it elegantly, command 5 will fail with a NoSuchElementException if that form field is not there on the page currently in the browser.
Keep in mind that we aren't yet doing any testing, but are just scripting some browser automation.
What is needed here is a way of modeling the browser state, and providing a mechanism for the script to interact with that model, instead of directly with the browser (via WebDriver commands). And as you probably already know, the model you need is a Page Object Model.
Application Wrappers and Page Object Models
An application wrapper is a package that models an application under test, and provides a programmatic interface to interacting with that app. If you have more than one application that you test, wrappers provide a way to interact with multiple applications from the context of scripts. An application wrapper provides an API for your test code to interact with the application.
A common design pattern for the logic in a wrapper for web apps is the Page Object Model (POM). The premise behind a POM is that the model representation for a page should "know" about itself, and should provide mechanisms for acting on itself. This supports thinking about programmatic interactions along the lines of "I have this search page that I consider as a class instance in my code, and it supports actions like searching, and after having searched I have a new class instance for the search results page, and that page supports properties like the number of results and actions like page through the results."
The POM implementation is usually a hierarchical tree of classes supporting inheritance and abstraction, along with methods to support interactions. The wrapper will also likely include utility methods for parsing and handling the pages and their data.
A wrapper with a POM supports this more robust interaction pattern:
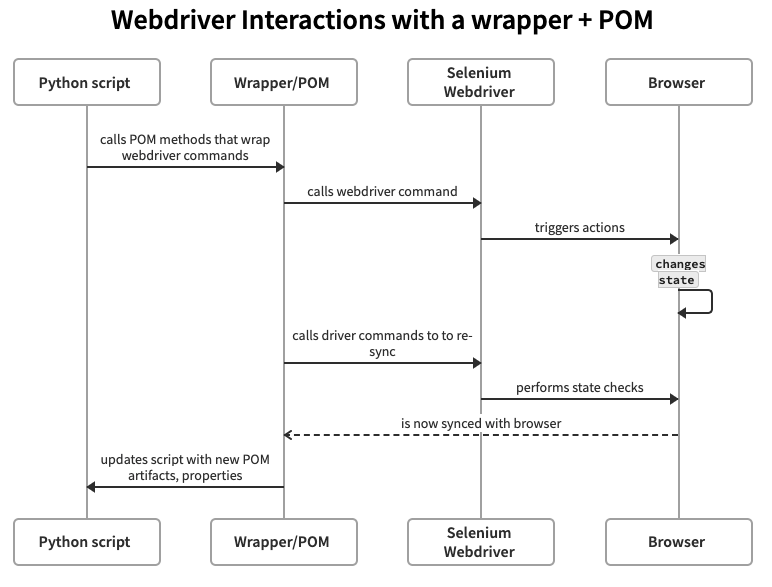
The significant difference is that the POM mediates the script's interactions with the browser, and keeps the script's expectations for the browser state in-sync with the browser's actual state.
There is nothing incorrect about the first, simpler, pattern. It is an obvious way to start writing browser automation: that is, putting more emphasis on code logic in the test case. This approach is a quick and dirty way to explore new application surfaces, and as the test approach gets clarified and as the automator gets more skilled and more comfortable with framework abstractions, refactor this kind of logic out of the test case. The drawbacks to the simpler approach is that the WebDriver code is more brittle, the logic is not re-purposable, and the test cases get closely coupled to the interfaces being tested.
Design Considerations for a Wrapper + POM
There are countless tutorials on writing POMs, and this is not a tutorial, so I'll stick to design issues and not providing all the code to make this work.
An application wrapper is not a test artifact, even though it supports the testing of the application. Test logic should live in the test case, not in the wrapper. Likewise, the Page Object Model is used by the test code, but it is not a test. The wrapper/POM mediates interactions with the browser.
Because the wrapper is not a test artifact, any checks we perform in the POM should raise exceptions on failure; we should not be performing assertions in the POM.[4] While WebDriver commands will raise exceptions on various failures, it's a good idea to trap those and raise more communicative, accurate, and relevant custom exceptions that will help the users of your automation to better understand what went wrong and what the error means.
For example, the following is a custom exception to raise when a WebDriver command to find an element fails, if the presence of that element is used as a validation that the page displayed in the browser matches the expected page object.
class PageIdentityException(Exception):
# Raise when a page object fails its identity validations
def __init__(self, errors=None):
Exception.__init__(self, errors)
self.errors = errorsThe following code example shows a POM for the DuckDuckGo home page, with comments inline:
class BasePageObject(object):
domain = 'www.duckduckgo.com'
class HomePage(BasePageObject):
def __init__(self, driver):
self.url = 'https://' + self.domain + '/'
self.driver = driver
def load(self):
self.driver.get(self.url)
def verify_self(self):
# set identity check expectations
expected_title = 'DuckDuckGo — Privacy, simplified.'
expected_domain = self.domain
# actual results
actual_title = self.driver.title
actual_domain = domain_from_url[2]
# validate expectations
if actual_title == expected_title
and actual_domain == expected_domain"
return True
else:
msg = f"ERROR: DuckDuckGo home page did NOT self-validate identity. "
f"Expected '{expected_title}' + '{expected_domain}', but got "
f"'{actual_title}' + '{actual_domain}'."
raise PageIdentityException(msg)
def search_for(self, text):
# grab the search form
search_input = self.driver.find_element(By.CLASS_NAME, 'js-search-input')
# pass in the search string
search_input.send_keys(text)
# submit the search form
search_input.submit()
class SearchResultsPage(BasePageObject):
def __init__(self, driver, text):
self.driver = driver
self.search_text = text
def verify_self(self):
# set identity check expectations
expected_title = f"{self.search_text} at DuckDuckGo"
expected_url = f"https://{self.domain}?q={self.search_text.replace(' ', '+')}"
# actual results
actual_title = self.driver.title
actual_url = driver.current_url
# validate expectations
if actual_title == expected_title
and actual_url.startswith(expected_url)
return True
else:
msg = f"ERROR: DuckDuckGo search page did NOT self-validate identity. "
f"Expected '{expected_title}' + '{expected_url}', but got "
f"'{actual_title}' + '{actual_url}'."
raise PageIdentityException(msg)
def scrape_results_list(self):
"""
Pull out the document titles, which may be displayed as truncated.
:return result_titles: list, str titles for each returned result
"""
sel_result_items = 'js-result-title-link'
raw_results = self.driver.find_elements(By.CLASS_NAME, sel_result_items)
result_titles = [item.text for item in raw_results]
return result_titlesThis excerpt is simplified; the full code is here: Example DuckDuckGo POM.
Calling code, whether in a test case or another module, would look like this:
import pytest
from welkin.framework.exceptions import PageIdentityException
from welkin.apps.examples.duckduckgo.noauth import pages as POs
class ExampleTests(object):
def test_duckduckgo(self, driver):
# `driver` is a pytest fixture for a WebDriver instance
# declared in conftest.py
query = 'test case design in python'
# instantiate the home page object
home_page = POs.HomePage(driver, firstload=True)
# load home page in browser and refresh the PO instace
home_page = home_page.load()
# perform search, which returns a page object for the results page
results_page = home_page.search_for(query)
# get the search results titles
result_titles = results_page.scrape_results_list()
# some checkpoints to validate search results
# 1. we should have some results
assert len(result_titles) > 0, f"No results found for '{query}'"
# 2. at least some of the results should be somewhat relevant
raw_relevant_results = []
for token in query.split(' '):
for title in result_titles:
if token.lower() in title.lower():
raw_relevant_results.append(title)
relevant_results = list(set(raw_relevant_results)) # de-dupe
assert len(relevant_results) > 5, \
f"Only {len(relevant_results)} relevant results found, hoped for 5"I compare four approaches to testing this functionality, starting simple and getting progressively more abstracted, at Example DuckDuckGo tests.
Notes
- An interactive Python shell like IPython or the stock IDLE is the very best way to explore the commands needed to accomplish what you are trying to automate; experimenting in the shell to figure out the selectors and page properties is far more efficient that endless code-save-run attempts at writing code in a file. Using IPython could be your test automator superpower. Also, tab-completion for object properties and methods is very, very useful.
- These sequence diagrams were generated using the awesome and free tool swimlanes.io.
- Working draft for the W3C's WebDriver specification: https://www.w3.org/TR/webdriver2/.
- This point that assertions belong only in test cases is an ongoing discussion in the programming world, and I'm not going to argue it out here. My personal position, based on my experience, is clear.